Working with data is hard and repetitive. That is why we are more than happy to announce the launch of the alpha version of our DBpedia Databus, a way that simplifies working with data.
We have studied the data network for already 10 years and we conclude that organizations with open data are struggling to work together properly. Even though they could and should collaborate, they are hindered by technical and organizational barriers. They duplicate work on the same data. On the other hand, companies selling data cannot do so in a scalable way. The consumers are left empty-handed and trapped between the choice of inferior open data or buying from a jungle-like market.
We need to rethink the incentives for linking data
Vision
We envision a hub, where everybody uploads data. In that hub, useful operations like versioning, cleaning, transformation, mapping, linking, merging, hosting are done automagically on a central communication system, the bus, and then again dispersed in a decentral network to the consumers and applications. On the Databus, data flows from data producers through the platform to the consumers (left to right), any errors or feedback flows in the opposite direction and reaches the data source to provide a continuous integration service and improves the data at the source.
The DBpedia Databus is a platform that allows exchanging, curating and accessing data between multiple stakeholders. Any data entering the bus will be versioned, cleaned, mapped, linked and its licenses and provenance tracked. Hosting in multiple formats will be provided to access the data either as dump download or as API.
Publishing data on the Databus means connecting and comparing your data to the network
If you are grinding your teeth about how to publish data on the web, you can just use the Databus to do so. Data loaded on the bus will be highly visible, available and queryable. You should think of it as a service:
- Visibility guarantees, that your citations and reputation goes up.
- Besides a web download, we can also provide a Linked Data interface, SPARQL-endpoint, Lookup (autocomplete) or other means of availability (like AWS or Docker images).
- Any distribution we are doing will funnel feedback and collaboration opportunities your way to improve your dataset and your internal data quality.
- You will receive an enriched dataset, which is connected and complemented with any other available data (see the same folder names in data and fusion folders).
How it works at the moment
Integration of data is easy with the Databus. We have been integrating and loading additional datasets alongside DBpedia for the world to query. Popular datasets are ICD10 (medical data) and organizations and persons. We are still in an initial state, but we already loaded 10 datasets (6 from DBpedia, 4 external) on the bus using these phases:
- Acquisition: data is downloaded from the source and logged in.
- Conversion: data is converted to N-Triples and cleaned (Syntax parsing, datatype validation, and SHACL).
- Mapping: the vocabulary is mapped on the DBpedia Ontology and converted (We have been doing this for Wikipedia’s Infoboxes and Wikidata, but now we do it for other datasets as well).
- Linking: Links are mainly collected from the sources, cleaned and enriched.
- IDying: All entities found are given a new Databus ID for tracking.
- Clustering: ID’s are merged onto clusters using one of the Databus ID’s as cluster representative.
- Data Comparison: Each dataset is compared with all other datasets. We have an algorithm that decides on the best value, but the main goal here is transparency, i.e. to see which data value was chosen and how it compares to the other sources.
- A main knowledge graph fused from all the sources, i.e. a transparent aggregate.
- For each source, we are producing a local fused version called the “Databus Complement”. This is a major feedback mechanism for all data providers, where they can see what data they are missing, what data differs in other sources and what links are available for their IDs.
- You can compare all data via a web service.
Contact us via dbpedia@infai.org if you would like to have additional datasets integrated and maintained alongside DBpedia.
From your point of view
Data Sellers
If you are selling data, the Databus provides numerous opportunities for you. You can link your offering to the open entities in the Databus. This allows consumers to discover your services better by showing it with each request.
Data Consumers
Open data on the Databus will be a commodity. We are greatly downing the cost of understanding the data, retrieving and reformatting it. We are constantly extending ways of using the data and are willing to implement any formats and APIs you need. If you are lacking a certain kind of data, we can also scout for it and load it onto the Databus.
Is it free?
Maintaining the Databus is a lot of work and servers incurring a high cost. As a rule of thumb, we are providing everything for free that we can afford to provide for free. DBpedia was providing everything for free in the past, but this is not a healthy model, as we can neither maintain quality properly nor grow.
On the Databus everything is provided “As is” without any guarantees or warranty. Improvements can be done by the volunteer community. The DBpedia Association will provide a business interface to allow guarantees, major improvements, stable maintenance, and hosting.
License
Final databases are licensed under ODC-By. This covers our work on recomposition of data. Each fact is individually licensed, e.g. Wikipedia abstracts are CC-BY-SA, some are CC-BY-NC, some are copyrighted. This means that data is available for research, informational and educational purposes. We recommend to contact us for any professional use of the data (clearing) so we can guarantee that legal matters are handled correctly. Otherwise, professional use is at own risk.
Current Statistics
The Databus data is available at http://downloads.dbpedia.org/databus/ ordered into three main folders:
- Data: the data that is loaded on the Databus at the moment
- Global: a folder that contains provenance data and the mappings to the new IDs
- Fusion: the output of the Databus
Most notably you can find:
Update 21/8/2019: Data is now available via the Databus: https://databus.dbpedia.org/dbpedia/prefusion , but without external datasets, full paper here.
- Provenance mapping of the new ids in global/persistence-core/cluster-iri-provenance-ntriples/<http://downloads.dbpedia.org/databus/global/persistence-core/cluster-iri-provenance-ntriples/> and global/persistence-core/global-ids-ntriples/<http://downloads.dbpedia.org/databus/global/persistence-core/global-ids-ntriples/>
- The final fused version for the core: fusion/core/fused/<http://downloads.dbpedia.org/databus/fusion/core/fused/>
- A detailed JSON-LD file for data comparison: fusion/core/json/<http://downloads.dbpedia.org/databus/fusion/core/json/>
- Complements, i.e. the enriched Dutch DBpedia Version: fusion/core/nl.dbpedia.org/<http://downloads.dbpedia.org/databus/fusion/core/nl.dbpedia.org/>
(Note that the file and folder structure are still subject to change)
Sources
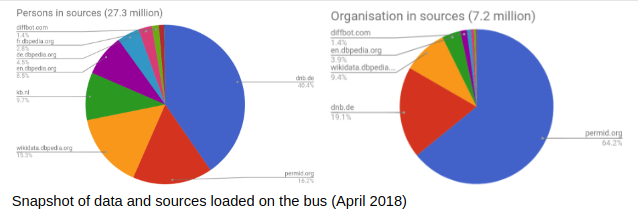
Upcoming Developments
- Include more existing data from DBpedia
- Renew all DBpedia releases in a separate fashion:
- Load all data in the comparison tool:
http://88.99.242.78:9000/?s=http%3A%2F%2Fid.dbpedia.org%2Fglobal%2F12HpzV&p=http%3A%2F%2Fdbpedia.org%2Fontology%2Farchitect&src=general
Update 21/08/2019: The comparison tool developed into a data browser hosted at https://global.dbpedia.org , source code - Load all data into a SPARQL endpoint
- Create a simple open source software that let’s everybody push data on the Databus in an automated way
Data market
- build your own data inventory and merchandise your data via Linked Data or via secure named graphs in the DBpedia SPARQL Endpoint (WebID + TLS + OpenLink’s Virtuoso database)
DBpedia Marketplace
- Offer your Linked Data tools, services, products
- Incubate new research into products
- Example: Support for RDFUnit (https://github.com/AKSW/RDFUnit created by the SHACL editor), assistance with SHACL writing and deployment of the open-source software
DBpedia and the Databus will transform Linked Data into a networked data economy
For any questions or inquiries related to the new DBpedia Databus, please contact us via dbpedia@infai.org
Yours,
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...