DBpedia Archivo is an online interface and augmented archive for all kinds of vocabularies. It automatically crawls for new ontologies, updates the already enlisted ontologies regularly and performs some useful tests to check the fitness of the vocabulary for the semantic web.
The ontologies and all additional data, are deployed on the Databus for easy access, the webservice provides some useful help for evaluation and usage. For a more specific explanation check out the Archivo paper.
Webservice Feature Overview
The Archivo web service provides a few handy tools to make it easier to use the ontologies deployed on the Databus:
- User ontology addition via the add service.
- Version overview and test results on the info-page of each ontology.
- A complete overview over the latest versions of all ontologies, their test results .
- A simple access to ontologies via redirection, check out the access section for more information.
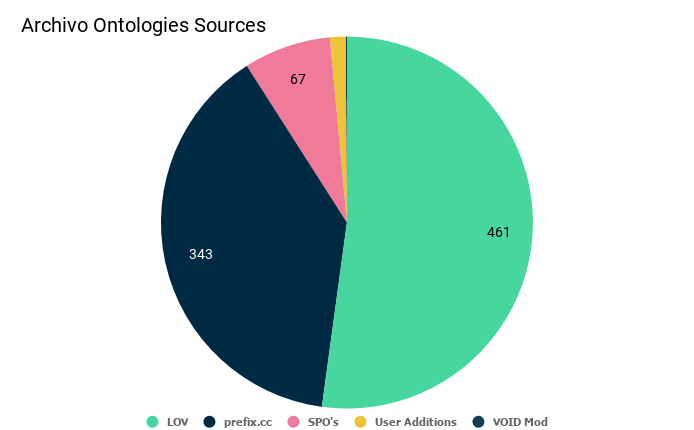
Ontology Sources
Right now Archivo consists of more than 850 Ontologies with more than 3.4 Million Triples. Archivo crawls regularly for new ontologies, right now in four different places:
- The LOV project is an ontology repository and most of the ontologies in Archivo stem from here.
- prefix.cc is a namespace lookup service for rdf and also provides non-information URIs
- Another source are the subject, predicates and objects of the Archivo ontologies themselfs
- Also users can add ontologies at the add service.
Prerequisites and Testing
Prerequisites
Right now an ontology needs to fulfill two prerequisites to be added to Archivo, either by crawling or the user addition:
- The URI must be accessible and the RDF content of the ontology must be reachable via content negotiation in any of these formats: RDF+XML, N-Triples or Turtle.
- The URI defined in the a owl:Ontology (or skos:ConceptScheme) triple must be the same as the original one. If that is not the case Archivo tries to parse the new URI
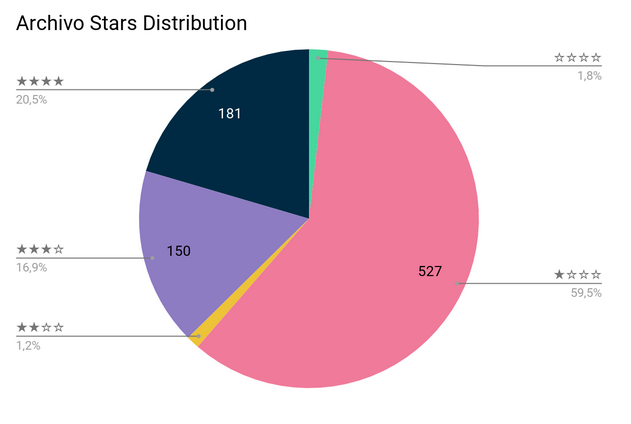
Archivo Star Rating
Archivo introduces a 4-star-rating to test the fitness of ontologies for the semantic web. the first two stars are the baseline for a proper ontology:
- The ontology must fulfill the following specifications:
- The non-information URI resolves to a machine readable format or a machine readable version of the ontology is deterministically discoverable by other common means.
- Download was successful
- Uses a common format implemented by Archivo (rdf+xml, turtle or n-triples)
- At least one format was found that parses with no or few (negligible) syntactical warnings
- A proper ontology declaration was found using rdf:type owl:Ontology and some form of license could be detected. A high degree of heterogeneity is permissible for this star regarding the used property/subproperty as well as object:license URI (resolvable linked data or web link), xsd:string or xsd:anyURI
If an ontology fulfills these first two stars, two further stars can be earned for using good practises:
- We require a homogenized license declaration using dct:license as object property with a URI (not string or anyURI).
- We measure the compatibility with currently available reasoners such as Pellet/Stardog (more to follow) and run available tasks such as consistency checks and classification.
Debugging Ontologies with Archivo
The info-page of each ontology displays each version, a link to the auto-generated documentation and the test results of them. The red ✘ marks a failed test, and a click on it reveals the related test report (in most cases SHACL validation reports).
Archivo provides, additionally to tests for the stars, a SHACL metadata check based on the requirements of the LODE documentation and the generated LODE documentation itself.
For proper debugging during development there is the possibility to add dev stage URI to your ontology (e.g a link to the raw github file of the ontology) via the triple
<non-information-resource> <http://archivo.dbpedia.org/trackThis> <devURI> .
The ontology gets deployed to the databus as the dev version and these dev versions get crawled far more often (about every ten minutes). These dev ontologies can be found in the dev list (works just the same as the normal list) or at the info page of the ontology (example of the Dbpedia Ontology).
Access
Easy Access
Archivo can be used as a simple ontology backup/versioning tool to always have an ontology in the correct version and in the desired format ready to use. A simple call of
http://archivo.dbpedia.org/download?o={ontologyURI}
will redirect you to the latest version of the given ontologyURI as an owl-file. Optionally the parameters for format (f={owl,ttl or nt}), version (v={version-timestamp}, e.g 2020.06.10-173500) and dev stage (dev) can be added to specify the ontology you want (example).
Complete List of Ontologies
Archivo provides a searchable list of all ontologies where you can compare all kinds of stats, the test results and download links of the latest version of each ontology. It also redirects to the info-page of the ontology, which displays all versions and their test results.
Using the Databus Stack
Since everything is deployed on the DBpedia Databus, the whole stack of Databus-tools can be used to access the vocabularies:
- The SPARQL-Endpoint: if you are familiar with SPARQL this can be pretty easy by using the structure of the Databus. A simple starting point could be this example.
- The Download Client: With this tool an arbitrarily large chunk of ontologies can be downloaded, for example by using some handy Databus collection like the latest-parsed-ontologies-collection.
- Dockerized DBpedia: Starts a Virtuoso instance with the RDF-contents of a Databus collection, so using the latest-parsed-ontologies-collection will result in a triple store with the contents of all Archivo-Ontologies.
- Did you consider this information as helpful?
- Yep!Not quite ...