
Spoiler alert: yes it can!
TLDR
Providing access to information is the main and most important purpose of the Web. Despite available easy-to-use tools (e.g., search engines, question answering) the accessibility is typically limited by the capability of using the English language.
In this work, we evaluate Knowledge Graph Question Answering (KGQA) systems that aim at providing natural-language access to data stored in Knowledge Graphs (KG). What makes this work special is that we look at questions in multiple languages. Mainly, we compare the results between the native support quality values and the values obtained while integrating machine translation (MT) tools. The evaluation results demonstrated that the monolingual KGQA systems can be effectively ported to the most of the considered languages with MT tools.
The Problem
Given recent statistics, only 25.9% of online users speak English. At the same time, 61.2% of the web content is published in the English language. Therefore, the users not capable of speaking or reading English have only limited access to the information provided on the Web. Hence, despite the disputed statistics, a clear gap of the information accessibility exists on the Web. This gap is referred to as the digital language divide.
Nowadays, whenever a user queries a search engine they expect to receive a direct answer. The direct answers functionality is based on the Question Answering (QA) methods and driven by knowledge graphs. In 2012, the Google Knowledge Graph was presented that powered Google’s direct answers. For example, when one asks Google “Who wrote Harry Potter?”, the following structured result is expected (see figure below).
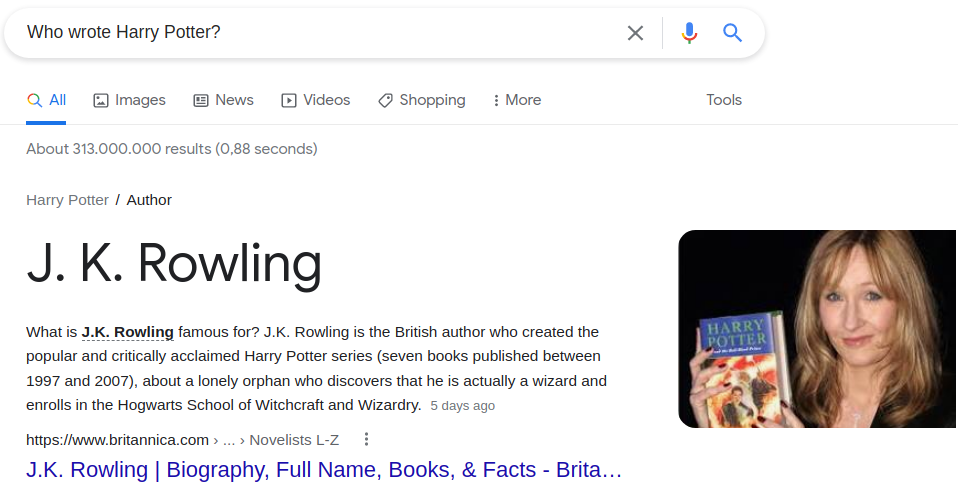
Google search result for query “Who wrote Harry Potter?” (screenshot by author)
These direct answers are more readable and satisfy the user’s information need right away, s.t., they don’t need to open each “relevant” web-page given by the search engine (as it was done before) and search for the requested information manually on the opened web-page. But if we ask the same very simple query in a low-resource language , e.g., Bashkir (Turkic language with ca. 1.4 million speakers), then the results are not really satisfying (see figure below).

Google search result for query “Who wrote Harry Potter?” in Bashkir language (screenshot by author)
Thus, there is an obvious limitation of knowledge accessibility on the Web that is visible for the people that don’t speak any “popular” language on a sufficient level. Therefore, in this article we address this problem in the context of Question Answering over Knowledge Graphs (KGQA) following the question “Are automatic machine translation tools usable to increase the accessibility of the knowledge on the Web for non-English speakers?”.
Approach
To answer the research question above, we conducted a large evaluation study. During our experiments, we follow a component-oriented methodology by reusing off-the-shelf QA components provided by the Qanary framework [1] to gain insights for the defined topic. As our goal is to evaluate KGQA systems that are adapted to an unsupported language via machine translation (MT) tools, we therefore need:
1. A set of multilingual KGQA systems supporting particular languages.
2. A set of high-quality questions written by native speakers in different languages (where two groups are required: one that is supported and one that is not supported by existing KGQA systems).
3. A set of MT tools that are able to translate questions given in unsupported languages into the supported ones.
For the first point, we used the following well-known systems: QAnswer [2], DeepPavlov KBQA [3], and Platypus [4]. For the second point, we used our QALD-9-Plus dataset [5] that has high-quality questions in English, German, Russian, French, Ukrainian, Belarusian, Lithuanian, Bashkir, and Armenian languages and the corresponding answers represented as SPARQL queries over DBpedia and Wikidata knowledge graphs. For the third point, we used Yandex Translate (commercial MT tool) and Opus MT models by Helsinki NLP (open source MT tool) [6]. The evaluation was done using the GERBIL platform [7]. Hence, the following experimental setup was built (see figure below).

Overview of the experimental setup (figure by author)
Results
From the experimental results, we clearly observe strong domination of English as a target translation language. In the majority of the experiments, translation of a source language to English gave the best QA quality results (e.g., German → English, Ukrainian → English).
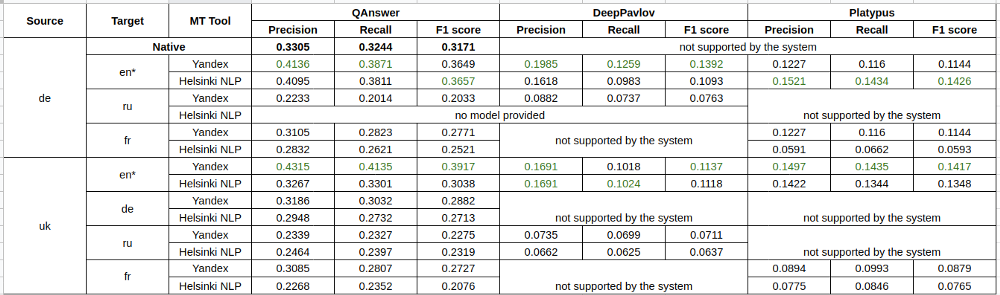
Experimental values for German and Ukrainian languages as source. The native questions are higlighted with bold text. The star (*) corresponds to the highest quality target language. The best values regarding the system and metric are color-coded with green (table by author).
In the very first case, where English was the source language, the best QA quality was achieved on the original (native) questions as using machine translation additionally was decreasing the QA quality (see figure below).

Experimental values for English language as source. The native questions are highlighted with bold text. The star (*) corresponds to the highest quality target language. The best values regarding the system and metric are color-coded with green (table created by author).
Only in the case where Lithuanian was the source language, the best target language regarding the QA quality turned up to be German (i.e., Lithuanian → German), while English also demonstrated reasonable quality (i.e., Lithuanian → English). Although the experiment was carefully designed, we considered this case as an outlier. Nevertheless, such outliers might have a significant impact while improving the answer quality of QA systems.

Experimental values for Lithuanian language as source. The native questions are highlighted with bold text. The star (*) corresponds to the highest quality target language. The best values regarding the system and metric are color-coded with green (table created by author).
Summary
Our main conclusion is that machine translation can be efficiently used for the purpose of establishing multilingual KGQA systems for the majority of languages. It turns out that the most optimal way of using MT tools is to just translate the source language (e.g. German, Russian, etc.) into English — this will result in the highest quality question answering process. Hence, even if the source and target languages are from the same group (e.g., Ukrainian → Russian — slavic group), it is better to translate them to English from the quality point of view. Despite our results and the concluded recommendation to extend the QA system by machine translation component, we would like to point the research community to many open questions that might affect the answer quality. Therefore, we plan to extend our experiments with additional languages. We welcome any input to help us expand this research.
If you want to see more detailed results, please see our recent paper: Aleksandr Perevalov, Andreas Both, Dennis Diefenbach, and Axel-Cyrille Ngonga Ngomo. 2022. Can Machine Translation be a Reasonable Alternative for Multilingual Question Answering Systems over Knowledge Graphs? In Proceedings of the ACM Web Conference 2022 (WWW ’22). Association for Computing Machinery, New York, NY, USA, 977–986. https://dl.acm.org/doi/10.1145/3485447.3511940
The corresponding video presentation is available here:
Acknowledgments
I would like to thank the co-authors of this work, namely: Andreas Both, Dennis Diefenbach and Axel-Cyrille Ngonga Ngomo.
Authors of the paper would like to thank all the contributors involved in the translation of the dataset, specifically: Konstantin Smirnov, Mikhail Orzhenovskii, Andrey Ogurtsov, Narek Maloyan, Artem Erokhin, Mykhailo Nedodai, Aliaksei Yeuzrezau, Anton Zabolotsky, Artur Peshkov, Vitaliy Lyalin, Artem Lialikov, Gleb Skiba, Vladyslava Dordii, Polina Fominykh, Tim Schrader, Susanne Both, and Anna Schrader. Additionally, authors would like to give thanks to Open Data Science community for connecting data science enthusiasts all over the world.
References
[1] Both, A., Diefenbach, D., Singh, K., Shekarpour, S., Cherix, D., & Lange, C. (2016, May). Qanary–a methodology for vocabulary-driven open question answering systems. In European Semantic Web Conference (pp. 625-641). Springer, Cham.
[2] Diefenbach, D., Migliatti, P. H., Qawasmeh, O., Lully, V., Singh, K., & Maret, P. (2019, May). QAnswer: a question answering prototype bridging the gap between a considerable part of the LOD cloud and end-users. In The World Wide Web Conference (pp. 3507-3510).
[3] Evseev, D. and Arkhipov, M.Y. (2020). Sparql query generation for complex question answering with bert and bilstm-based model, in: Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference Dialogue (pp. 270–282).
[4] Pellissier Tanon, T., Assunção, M. D. D., Caron, E., & Suchanek, F. M. (2018, June). Demoing Platypus–A multilingual question answering platform for Wikidata. In European Semantic Web Conference (pp. 111-116). Springer, Cham.
[5] Perevalov, A., Diefenbach, D., Usbeck, R., & Both, A. (2022, January). QALD-9-plus: A Multilingual Dataset for Question Answering over DBpedia and Wikidata Translated by Native Speakers. In 2022 IEEE 16th International Conference on Semantic Computing (ICSC) (pp. 229-234). IEEE.
[6] Tiedemann, J., & Thottingal, S. (2020, November). OPUS-MT–Building open translation services for the World. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation. European Association for Machine Translation.
[7] Usbeck, R., Röder, M., Ngonga Ngomo, A. C., Baron, C., Both, A., Brümmer, M., … & Wesemann, L. (2015, May). GERBIL: general entity annotator benchmarking framework. In Proceedings of the 24th international conference on World Wide Web (pp. 1133-1143).
- Did you consider this information as helpful?
- Yep!Not quite ...