
DBpedia Member Features – In the last few weeks, we gave DBpedia members the chance to present special products, tools and applications and share them with the community. We already published several posts in which DBpedia members provided unique insights. This week we will continue with Diffbot. They will present the Diffbot Knowledge Graph and various extraction tools. Have fun while reading!
by Diffbot
Diffbot’s mission to “structure the world’s knowledge” began with Automatic Extraction APIs meant to pull structured data from most pages on the public web by leveraging machine learning rather than hand-crafted rules.
More recently, Diffbot has emerged as one of only three Western entities to crawl a vast majority of the web, utilizing our Automatic Extraction APIs to make the world’s largest commercially-available Knowledge Graph.
A Knowledge Graph At The Scale Of The Web
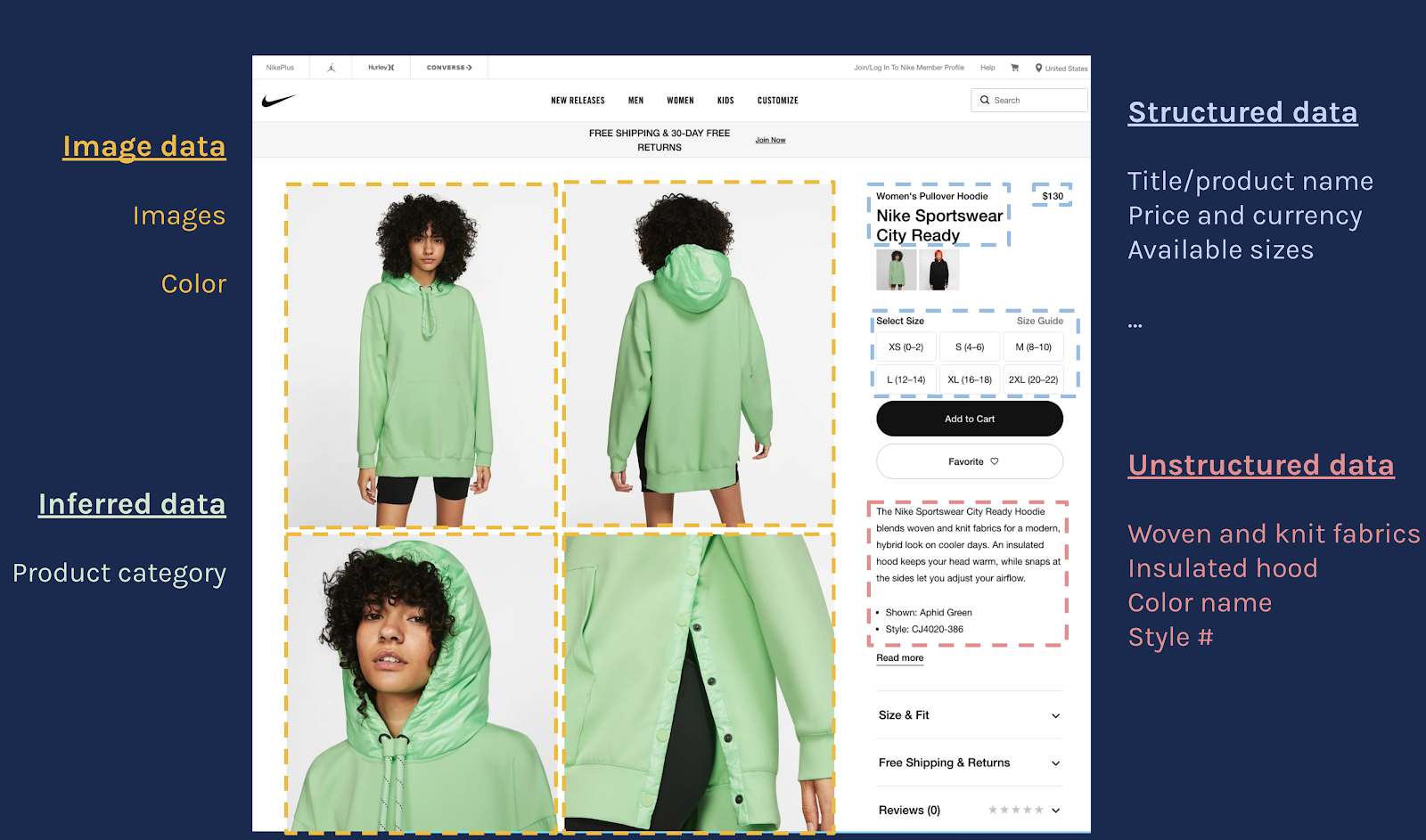
The Diffbot Knowledge Graph is automatically constructed by crawling and extracting data from over 60 billion web pages. It currently represents over 10 billion entities and 1 trillion facts about People, Organizations, Products, Articles, Events, among others.
Users can access the Knowledge Graph programmatically through an API. Other ways to access the Knowledge Graph include a visual query interface and a range of integrations (e.g., Excel, Google Sheets, Tableau).

Whether you’re consuming Diffbot KG data in a visual “low code” way or programmatically, we’ve continually added features to our powerful query language (Diffbot Query Language, or DQL) to allow users to “query the web like a database.”
Guilt-Free Public Web Data
Current use cases for Diffbot’s Knowledge Graph and web data extraction products run the gamut and include data enrichment; lead enrichment; market intelligence; global news monitoring; large-scale product data extraction for ecommerce and supply chain; sentiment analysis of articles, discussions, and products; and data for machine learning. For all of the billions of facts in Diffbot’s KG, data provenance is preserved with the original source (a public URL) of each fact.
Entities, Relationships, and Sentiment From Private Text Corpora
The team of researchers at Diffbot has been developing new natural language processing techniques for years to improve their extraction and KG products. In October 2020, Diffbot made this technology commercially-available to all via the Natural Language API.
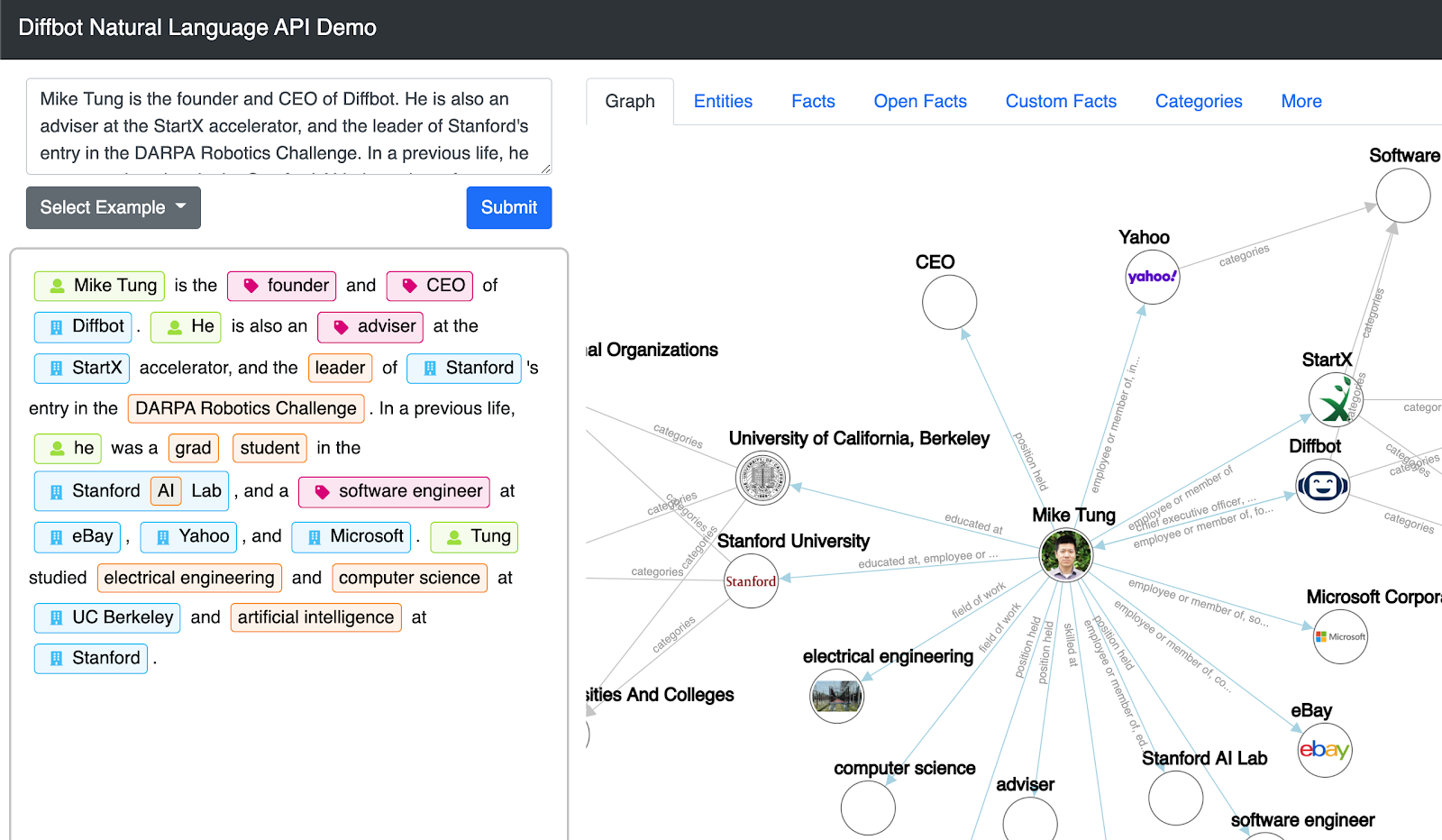
Our Natural Language API pulls out entities, relationships/facts, categories and sentiment from free-form texts. This allows organizations to turn unstructured texts into structured knowledge graphs.
Diffbot and DBpedia
In addition to extracting data from web pages, Diffbot’s Knowledge Graph compiles public web data from many structured sources. One important source of knowledge is DBpedia. Diffbot also contributes to DBpedia by providing access to our extraction and KG services and collaborating with researchers in the DBpedia community. For a recent collaboration between DBpedia and Diffbot, be sure to check out the Diffbot track in DBpedia’s Autumn Hackathon for 2020.
A big thank you to Diffbot, especially Filipe Mesquita for presenting their innovative Knowledge Graph.
Yours,
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...