DBpedia Member Features – In the coming weeks, we will give DBpedia members the chance to present special products, tools and applications and share them with the community. We will publish several posts in which DBpedia members provide unique insights. This week TerminusDB will show you how to use TerminusDB’s unique collaborative features to access DBpedia data. Have fun while reading!
by Luke Feeney from TerminusDB

This post introduces TerminusDB as a member of the DBpedia Association – proudly supporting the important work of DBpedia. It will also show you how to use TerminusDB’s unique collaborative features to access DBpedia data.
TerminusDB – an Open Source Knowledge Graph
TerminusDB is an open-source knowledge graph database that provides reliable, private & efficient revision control & collaboration. If you want to collaborate with colleagues or build data-intensive applications, nothing will make you more productive.
TerminusDB provides the full suite of revision control features and TerminusHub allows users to manage access to databases and collaboratively work on shared resources.
- Flexible data storage, sharing, and versioning capabilities
- Collaboration for your team or integrated in your app
- Work locally then sync when you push your changes
- Easy querying, cleaning, and visualization
- Integrate powerful version control and collaboration for your enterprise and individual customers.
The TerminusDB project originated in Trinity College Dublin in Ireland in 2015. From its earliest origins, TerminusDB worked with DBpedia through the ALIGNED project, which was a research project funded by Horizon 2020 that focused on building quality-centric software for data management.
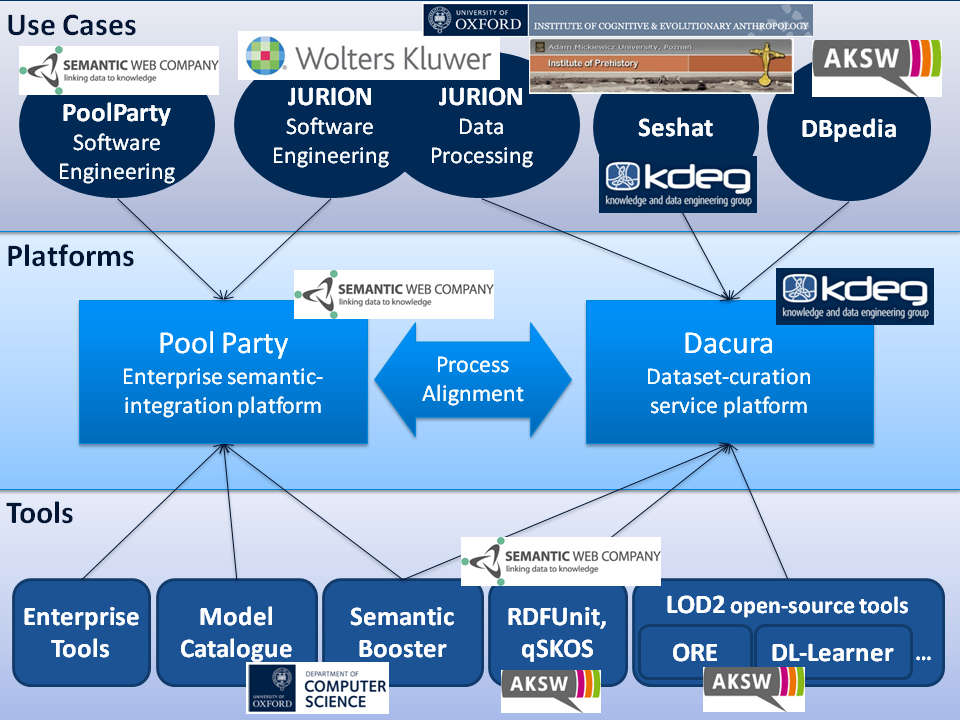
While working on this project and especially our work building the architecture behind Seshat: The Global History Databank, we needed a solution that could enable collaboration among a highly distributed team on a shared database whose primary function was the curation of high-quality datasets with a very rich structure. While the scale of data was not particularly large, the complexity was extremely high. Unfortunately, the linked-data and RDF toolchains was severely lacking – we evaluated several tools in an attempt to architect a solution; however, in the end we were forced to build an end-to-end ourselves.
Evolution of TerminusDB
In general, we think that computers are fantastic things because they allow you to leverage much more evidence when making decisions than would otherwise be possible. It is possible to write computer programs that automate the ingestion and analysis of unimaginably large quantities of data.
If the data is well chosen, it is almost always the case that computational analysis reveals new and surprising insights simply because it incorporates more evidence than could possibly be captured by a human brain. And because the universe is chaotic and there are combinatorial explosions of possibilities all over the place, evidence is always better than intuition when seeking insight.
As anybody who has grappled with computers and large quantities of data will know, it’s not as simple as that. Computers should be able to do most of this for us. It makes no sense that we are still writing the same simple and tedious data validation and transformation programs over and over ad infinitum. There must be a better way.
This is the problem that we set out to solve with TerminusDB. We identified two indispensable characteristics that were lacking in data management tools:
- A rich and universally machine-interpretable modelling language. If we want computers to be able to transform data between different representations automatically, they need to be able to describe their data models to one another.
- Effective revision control. Revision control technologies have been instrumental in turning software production from a craft to an engineering discipline because they make collaboration and coordination between large groups much more fault tolerant. The need for such capabilities is obvious when dealing with data – where the existence of multiple versions of the same underlying dataset is almost ubiquitous and with only the most primitive tool support.
TerminusDB and DBpedia
Team TerminusDB took part in the DBpedia Autumn Hackathon 2020. As you know, DBpedia is an extract of the structured data from Wikipedia.
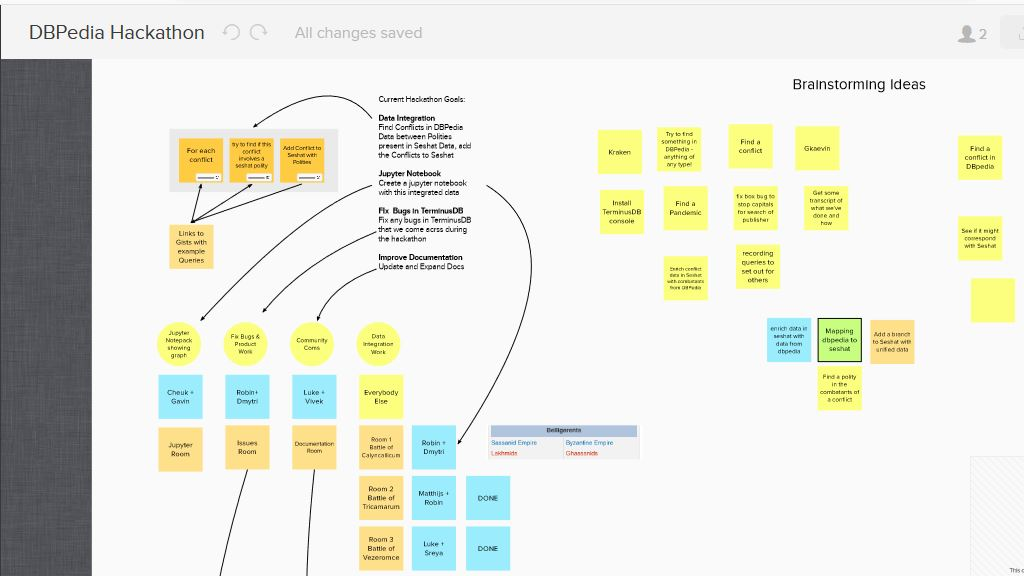
You can read all about our DBpedia Autumn Hackathon adventures in this blog post.
Open Source
Unlike many systems in the graph database world, TerminusDB is committed to open source. We believe in the principals of open source, open data and open science. We welcome all those data people that want to contribute to the general good of the world. This is very much in alignment with the DBpedia Association and community.
DBpedia on TerminusHub
TerminusHub is the collaborative point between TerminusDBs. You can push data to you colleagues and collaborators, you can pull updates (efficiently – just the diffs) and you can clone databases that are made available on the Hub (by the TerminusDB team or by others). Think of it as GitHub, but for data.
The DBpedia database is available on TerminusHub. You can clone the full DB in a couple of minutes (depending on your internet connection of course) and get querying. TerminusDB uses succinct data structures to compress everything so it makes sharing large database feasible – more technical detail here: https://github.com/terminusdb/terminusdb/blob/dev/docs/whitepaper/terminusdb.pdf for interested parties.
TerminusDB in the DBpedia Association
We will contribute to DBpedia by working to improve the quality of data available, by introducing new datasets that can be integrated with DBpedia, and by participating fully in the community.
We are looking forward to a bright future together.
A big thank you to Luke and TerminusDB presenting how TerminusDB works and how they would like to work with DBpedia in the future.
Yours,
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...