
DBpedia Member Features – Last year we gave DBpedia members the chance to present special products, tools and applications on the DBpedia blog. We have already published several posts in which our members provided unique insights. This week we will continue with Wallscope, they will show how you can derive value from existing data by coupling it with readily available open sources such as DBpedia. Have fun while reading!
by Antero Duarte, Lead Developer, Wallscope
Wallscope and DBpedia
Wallscope has been using DBpedia for many years – for example as part of our demos; to inform discussions with clients; and fundamentally to help people understand linked data and the power of knowledge graphs.
We also work with Natural Language Processing, and for us the intersection of these two areas of research and technology is extremely powerful. We can provide value to organisations at a low cost of entry, since resources like DBpedia and open source NLP models can be used with little effort.
We quickly realised that while linking entities, finding and expanding on keywords was interesting, this was more of an interesting novelty than a technology that would directly solve our clients’ problems.
For example, when speaking to an art gallery about classifying content, the prospect of automatically identifying artists’ names in text might appeal, because this is often a manual process. The gallery might also be interested in expanding artists’ profiles with things like their birth date and place, and the ability to find other artists based on properties of a previously identified artist. This is all interesting, but it’s mostly information that people looking at an artist’s work will already know.
The eureka moment was how we could use this information to expand and build on the things we already know about the artist. Presenting well-known aspects of the artist’s life alongside things that are not as obvious or well known, to create a wider story.
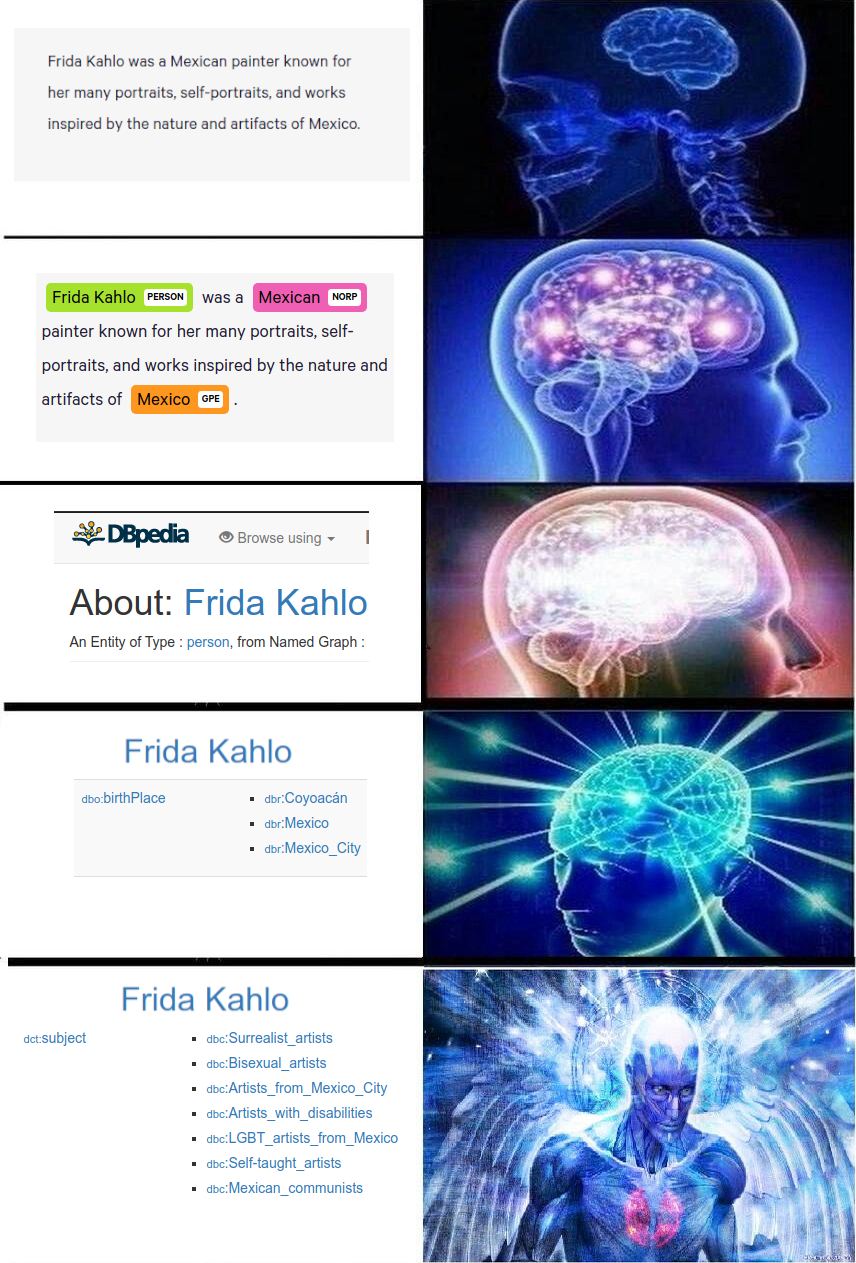
Frida Kahlo
We can take someone like Frida Kahlo and her audience and expose them to different facets of her work and life. By leveraging structure and connections between entities, rather than just the entities themselves, we can arrange previously created content in a different way and generate a new perspective, new insight and new value.
There’s a common expression in the data world that says that ‘data is the new oil’. While this is a parallel between the richest companies making their money from data nowadays rather than oil, as it used to be just a few decades ago, it is also true that: We mine data like oil. We treat data as a finite resource that we burn once or maybe refine and then burn, or maybe refine and turn into something else. But we don’t really think of data as reusable.
I’d like to propose that data is in fact a renewable resource. Like the wind…

If we take the previous example of the art gallery and how they manage the data they hold about Frida Kahlo. They might want to use the same content in different ways, and why wouldn’t they?
We have different ways of building a story around a single artist and their life. We can learn from DBpedia that Frida Kahlo is considered a surrealist artist, which allows us to build an exhibition about Surrealism.
But we can also learn that Frida Kahlo is a self-taught artist. We can build an exhibition centred around people who were self-taught and influential in different fields.
We can think of Frida’s personal life and how she is an LGBTQ+ icon for being openly and unapologetically queer, more specifically bisexual. This opens up an avenue to show LGBTQ+ representation in media throughout history.

For us this is one of the most powerful things about linked data, and it’s one of the easiest ways to show potential clients how they can derive value from existing data by coupling it with readily available open sources such as DBpedia.
This also promotes a culture of data reusability that actively goes against the problem of siloed data. Those gathering data don’t just think about their specific use case but rather about how their data can be useful for others and how they can best design it so it’s reusable elsewhere.
Lateral Search Technique
Besides the more obvious aspects of an open knowledge structure, an aspect that can sometimes be overlooked is the inherent hierarchy of concepts in something like Wikipedia’s (and consequently DBpedia’s) category pages. By starting at a specific level and generalising, we are able to find relevant information that relates to the subject laterally.
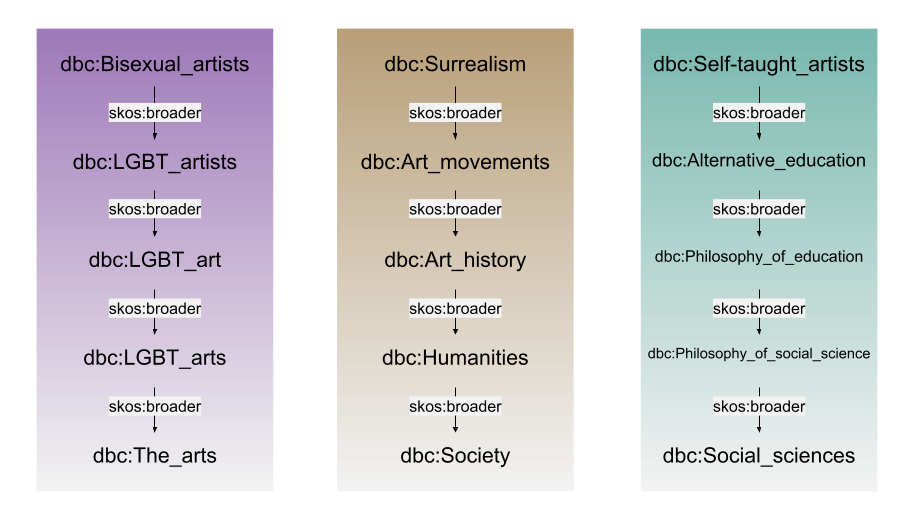
This process of lateral search can provide very good results, but it can also be a difficult process of testing out different mechanisms and finding the best way to select the most relevant connections, usually on a trial-and-error basis. Over the years we have used this lateral search technique as a more nuanced approach to topic classification that doesn’t require explicit training data, as we can rely on DBpedia’s structure rather than training data to make assertions.
With the trial-and-error approach Wallscope has created a set of tools that helps us iterate faster based on the use case for implementations of combined Natural Language Processing and structure mining from knowledge graphs.
Data Foundry
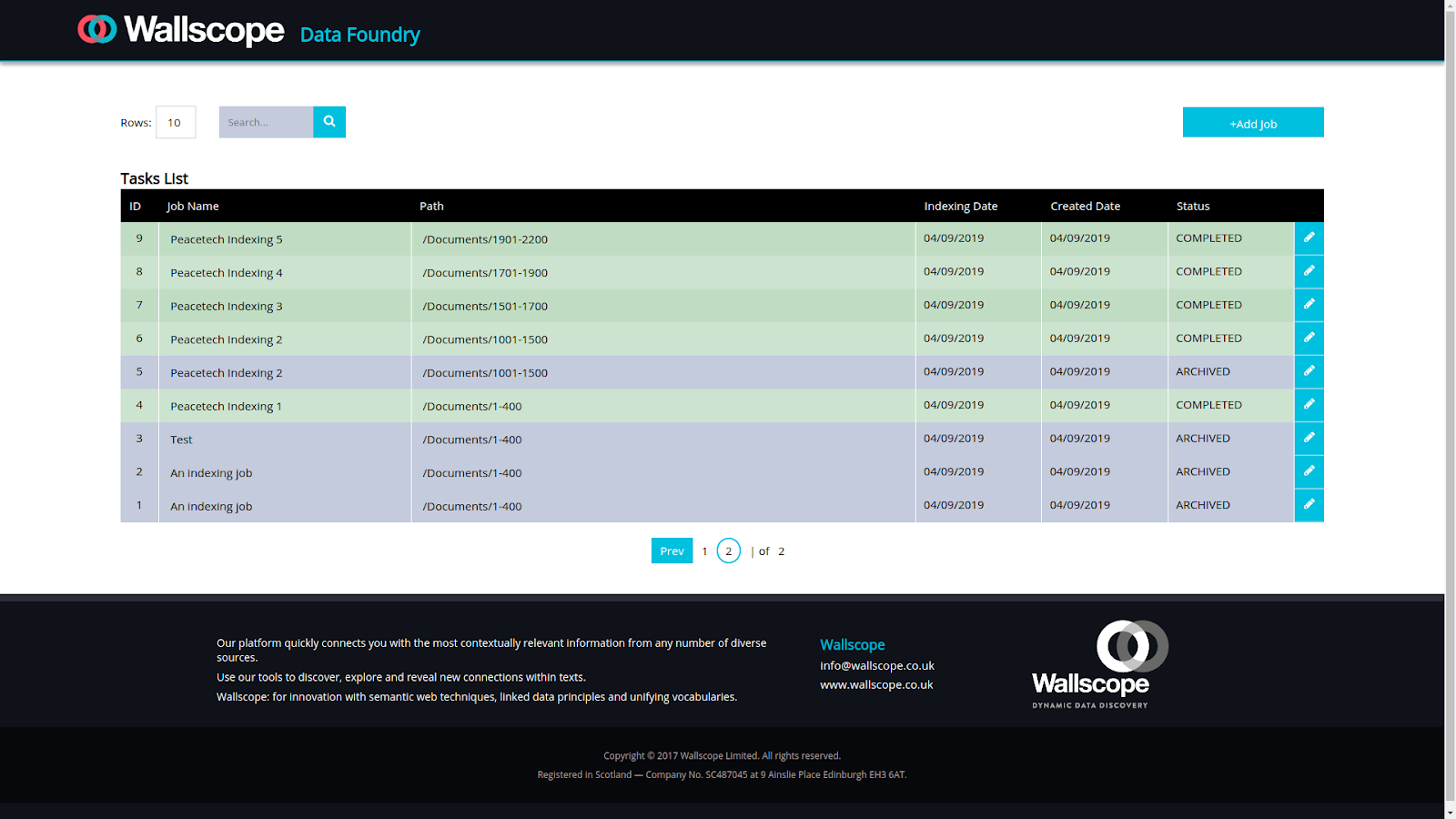
Data Foundry is Wallscope’s main packaged software offering for knowledge graph creation and manipulation. It is an extendable platform that is modular by design and scalable across machine clusters. Its main function is to act as a processing platform that can connect multiple data sources (usually a collection of files in a file system) to a single knowledge graph output (usually an RDF triplestore). Through a pipeline of data processors that can be tailored to specific use cases, information is extracted from unstructured data formats and turned into structured data before being stored in the knowledge graph.
Several processors in Data Foundry use the concept of structure mining and lateral search. Some use cases use DBpedia, others use custom vocabularies.
STRVCT
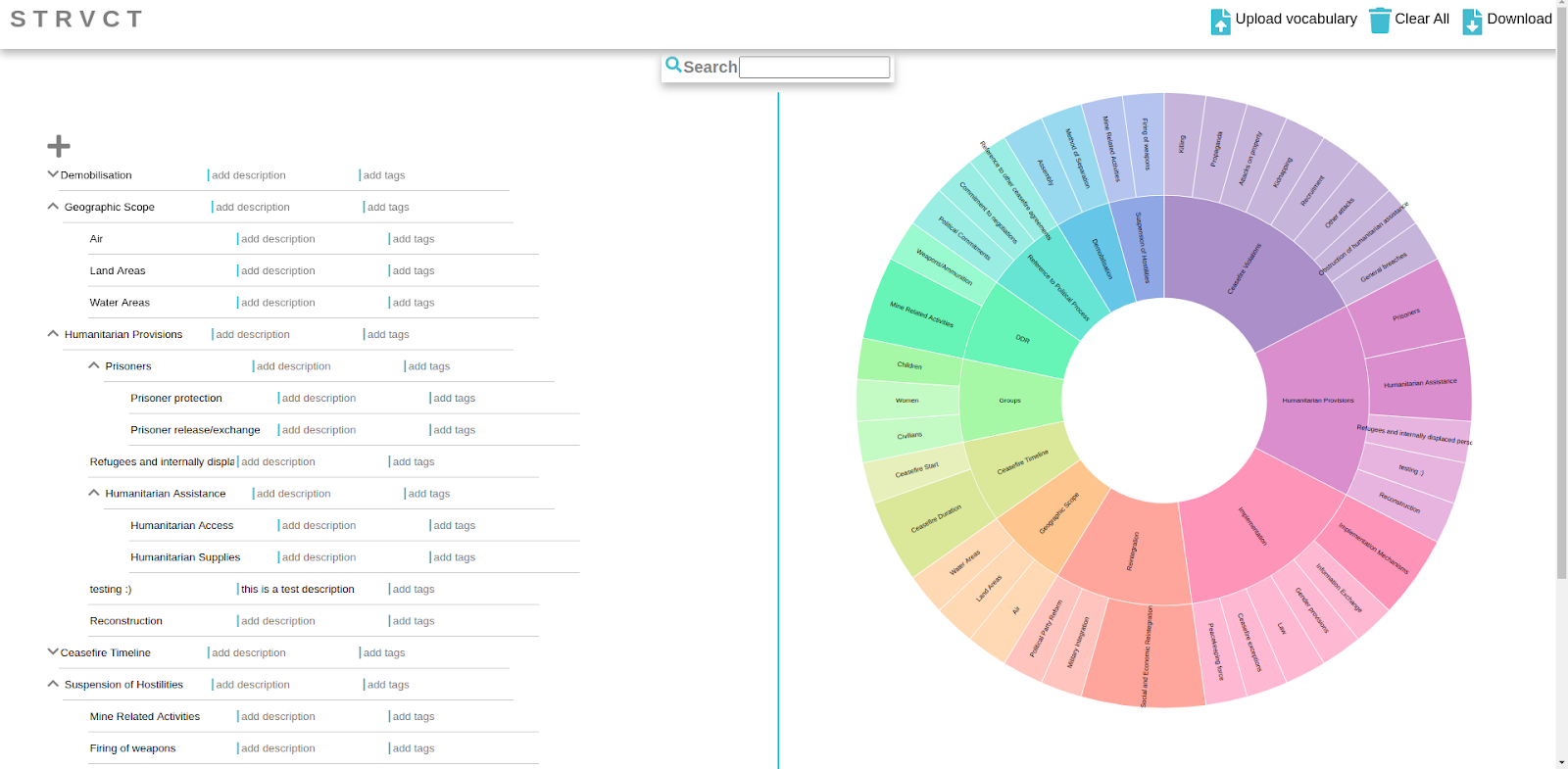
STRVCT is Wallscope’s structured vocabulary creation tool. It aims to allow any user to create/edit SKOS vocabularies with no prior knowledge of RDF, linked data, or structured vocabularies. By virtue of its function, STRVCT gives users ownership of their own data throughout the development process, ensuring it is in the precise shape that they want it to be in.
STRVCT is a stepping stone in Wallscope’s pipeline – once a vocabulary is created, it can be processed by Data Foundry and used with any of our applications.
HiCCUP
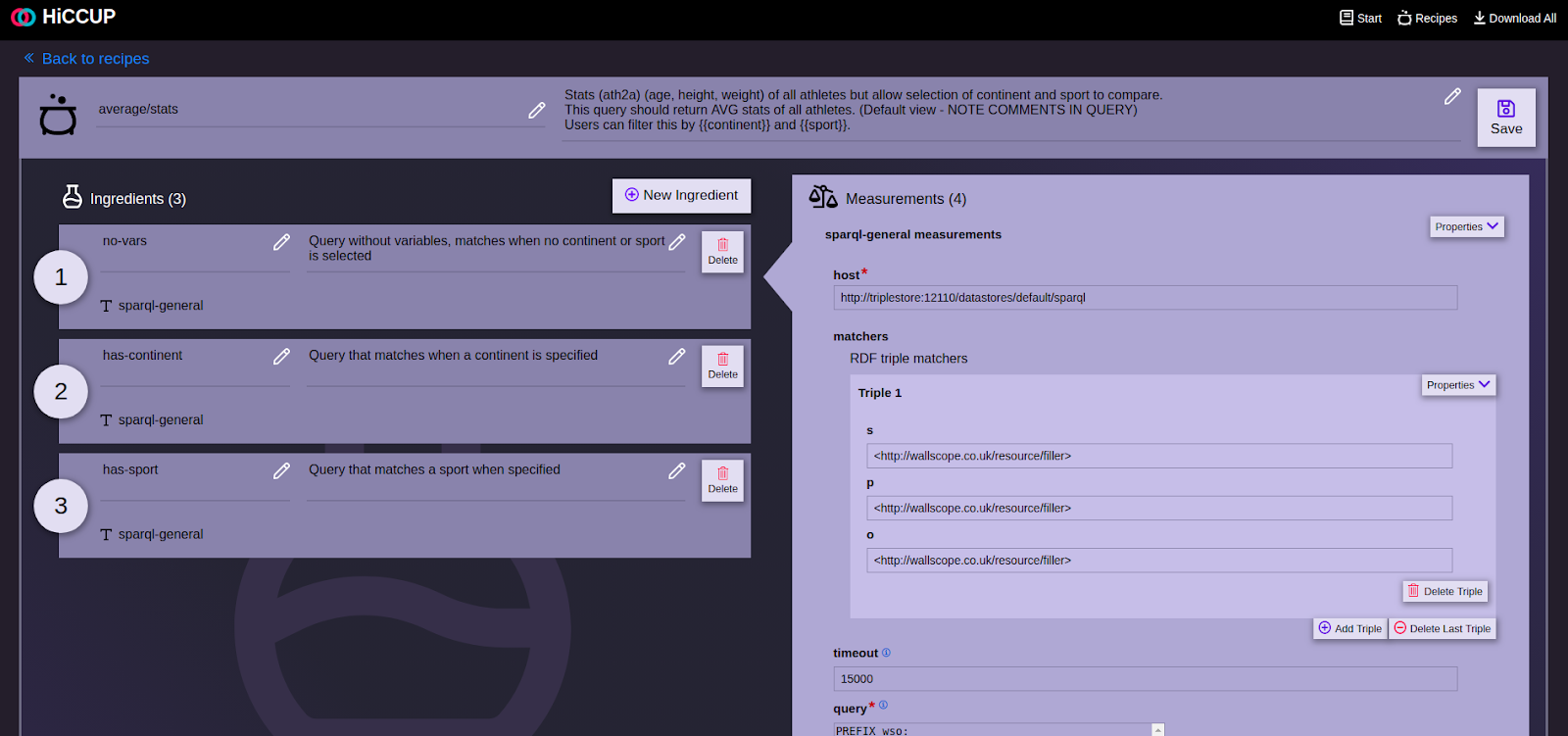
Standing for Highly Componentised Connection Unification Platform, HiCCUP is the “glue” in many of Wallscope’s projects and solutions.
It gives users the ability to create connections to SPARQL endpoints for templated queries and RDF manipulation and exposes those templates as an API with RDF outputs. The latest version also allows users to connect to a JSON API and real time conversion to RDF. This has proven useful in integrating data sources such as IoT device readings into knowledge graph environments.
Pronto
Pronto was created to overcome the challenges related to the reuse of ontologies. It is an open-source ontology search engine that provides fuzzy matching across many popular ontologies, originally selected from the prefix.cc user-curated “popular” list, along with others selected by Wallscope.
Pronto has already proved a reliable internal solution used by our team to shorten the searching process and to aid visualisation.
If you’re interested in collaborating with us or using any of the tools mentioned above, send an email to contact@wallscope.co.uk
You can find more Wallscope articles at https://medium.com/wallscope and more articles written by me at https://medium.com/@anteroduarte
A big thank you to Wallscope, especially Antero Duarte for presenting how to extract knowledge from DBpedia and for showcasing cool and innovative tools.
Yours,
DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...