
On Tuesday the 2nd of May, the DBpedia team organized the second edition of the DBpedia tutorial at the Knowledge Graph Conference (KGC) 2022. This year Johannes Frey made his way to New York and gave the tutorial on site. Milan Dojchinovski and Jan Forberg joined online. The ultimate goal of the tutorial was to teach the participants all relevant technology around DBpedia, the knowledge graph, the infrastructure and possible use cases. The tutorial aimed at existing and potential new users of DBpedia, developers that wish to learn how to replicate DBpedia infrastructure, service providers, data providers as well as data scientists.
Following, we will give you a brief retrospective about the tutorial. For further details of the presentations follow the link to the slides.
Session 1: DBpedia in a Nutshell
The tutorial was opened by Milan Dojchinovski (InfAI / DBpedia Association / CTU in Prague) with the DBpedia in a Nutshell session. In a 45 min session Milan presented a DBpedia historical Wrap-up, explained how a DBpedia triple is born as well as demonstrated the power of SPARQL and the DBpedia KG.
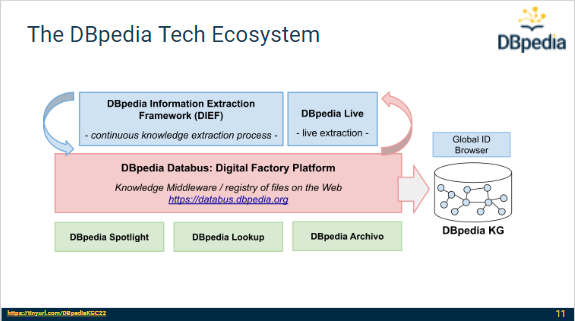
Session 2: DBpedia Tech Stack
After a short break, Jan started the DBpedia Tech Stack Session by giving an overview about the DBpedia technology stack. Furthermore, he explained the use of DBpedia for Automatization and Data Pipeline Creation. This included an explanation of Databus, possible ways to automate data tasks and examples such as knowledge extraction and knowledge fusion. After that, he got to the creation of a simple data flow using the Databus. This was about creation of new data, publishing the data on the Databus, aggregation and usage in SPARQL service via docker.
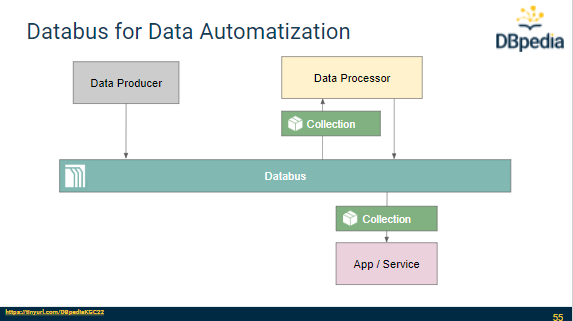
Session 3: Deployment on corporate infrastructure
In the third session Johannes started by presenting technical details in relation to Databus like identifiers, DataIDs and Mods. He also addressed DBpedia Databus popular datasets, where to find DBpedia datasets, how the DBpedia KG partitions are organized as well as popular data collections. As the tutorial came to an end, he explained how to self-host critical services including creation of a custom copy of the latest-core collection, (i.e. a subset of the DBpedia KG) and how to set up a corporate Databus instance.
In case you missed the event, our presentation is also available on the DBpeda event page. Further insights, feedback and photos about the event are available on Twitter (#DBpediaTutorial hashtag).
Stay safe and check Twitter or LinkedIn. Furthermore, you can subscribe to our Newsletter for the latest news and information around DBpedia.
Yours DBpedia Association
- Did you consider this information as helpful?
- Yep!Not quite ...