
Business Information Systems Institute Ltd
I2G – introducing quality to DBpedia
About the member
I2G is a Polish SME established in 2006 by researchers in the area of information systems. It is a spin-off set up to conduct innovative projects with required strong research involvement and potential for commercialization and its main capital is the know-how of its founders.
The mission of the company is to create innovative IT technologies and their application in business. I2G is a project-oriented organization that both reacts to and creates opportunities in environment, gathering knowledge and resources necessary to conduct the project and bring concrete results.
It has successfully completed several projects dealing with various types of information systems, committed research experience and knowledge of its founders and applied modern technologies to create advanced web applications. In years 2011-2014 it was part of the EU’s 7FP project: LOD2 – Creating Knowledge out of Interlinked Data. It is currently involved in COST action Distributed Knowledge Graphs.
Topics
Main focus of I2G concerning the contribution to DBpedia is: quality and references. Both topics are in fact related as improving the quality also requires assessing the sources of information.
The first topic – quality – concerns building and training machine learning models for assessment of the quality of Wikipedia pages. We base on grades provided by community of Wikipedia users and editors. Basically, we are looking for features that are good predictors for article being featured article (FA) or good article (GA). There are differences in grading systems between languages therefore for each language a separate model is constructed. Currently we support 55 languages. We also consider popularity as the related factor for quality assessment. Popular articles, as visited by many users, tend to be corrected more often than less popular ones.
The second topic – references – involves extraction of references from Wikipedia articles and assessing their reliability by looking into external databases like Crossref or Altmetric. References are used not only in text of article but also in infoboxes. Therefore, they can be useful for checking the reliability and timeliness of the provided data. They are also a building block in Wikidata. Additional cross-language statistics are provided where well-recognized identifiers are used, e.g. DOI, PubMed, arXiv, ISBN.
Quality – Wikirank
Results of our analyses are presented in a dedicated website http://wikirank.net. Numbers can be studied by language or by category. When first opened, data for English Wikipedia is displayed. Language is selected by clicking appropriate menu item on the left. For selected language the most popular articles for a given day are displayed. There is also a global popularity summary as presented in the figures below, comparing English and Spanish.
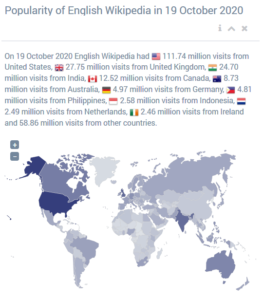
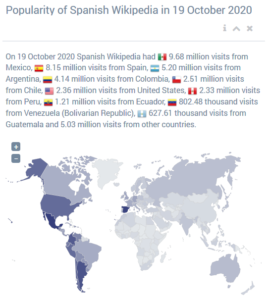
Source: http://wikirank.net/en/ , http://wikirank.net/es/
We also provide on overall distribution of quality of articles per language. The figures below compare German and Polish.
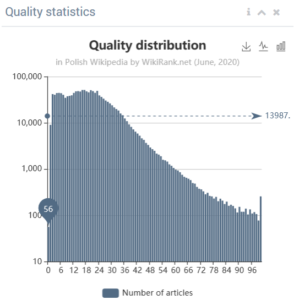
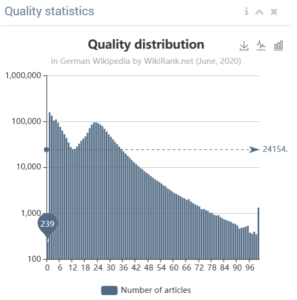
Source: http://wikirank.net/de, http://wikirank.net/pl
There are also several categories for which we build a separate ranking of popularity. The figure below presents an example for cryptocurrencies.
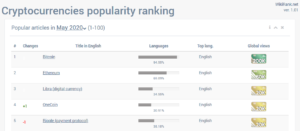
Source: http://wikirank.net/top/crypto
By choosing a specific article, either from ranking or by search, it is possible to study its detailed statistics.
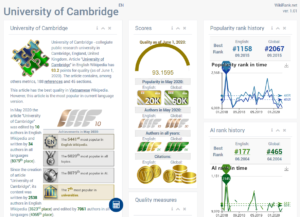
Source: http://wikirank.net/en/University%20of%20Cambridge
Quality – Infoboxes
We can assume that pages of high quality contain also infoboxes of high quality. Infoboxes themselves can also be assessed based on completeness or timeliness of data. Therefore, based on our quality models it is possible to identify infoboxes with data of higher quality than related infoboxes from other language versions.
The website http://infoboxes.net/ allows searching for a specific articles in a selected language and then display its infoboxes in a context. The figure below shows an example for city of Porto in Portuguese.
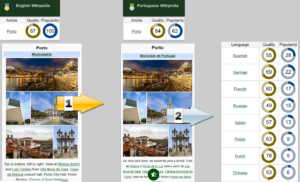
Source: http://infoboxes.net/pt/Porto
References – Bestref
A recent addition to our toolkit is the website http://bestref.net/. It assesses popularity and reliability of the sources, using one of the models based on frequency of usage (F), cumulative page views (PR) or authors (AR). The most popular sources based on PR-model in all languages is as follows:
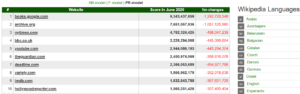
Source: http://bestref.net/
Ranking of sources differ by countries. Below we show top sources in Polish, German, Dutch and French.
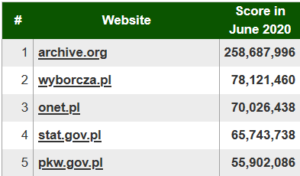
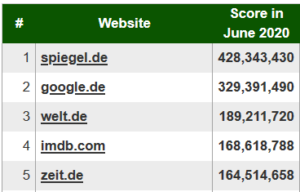
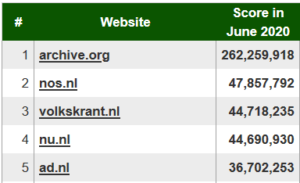
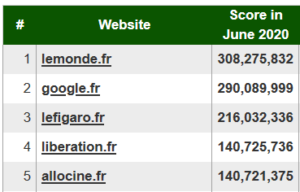
Source: http://bestref.net/pl, http://bestref.net/de, http://bestref.net/nl, http://bestref.net/fr.
The ranking is also provided for scientific publications with DOI numbers, for each language version separately. Figure below lists top mostly cited publications in Chinese Wikipedia.
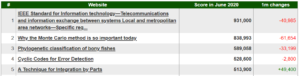
Source: http://bestref.net/zh/
Specific DOI number can be queried for detailed statistics about popularity scores and ranking. The figure below shows a report for “A Catalog of Neighboring Galaxies”, identified by DOI 10.1086/382905.
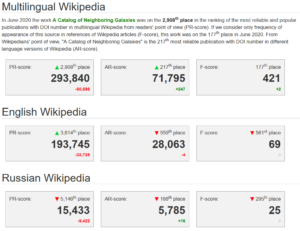
Source: http://bestref.net/doi/10.1086/382905