The most common way of consuming DBpedia is using the public endpoint service, which provides the latest release of DBpedia. While this is sufficient in many cases, some applications may require very recent data (i.e., more recent than the latest release), and/or require a lot of requests to the DBpedia servers, which imposes a high load on the public service.
As an alternative, it is possible to host a local copy of DBpedia, and to even extract fresher releases and/or use DBpedia Live. However, hosting a local copy requires a lot of computational resources. DBpedia on Demand follows a different strategy: when requesting a DBpedia resource, that resource is created on the fly by retrieving the corresponding pages from Wikipedia and converting them to RDF at request time. That way, the data is always 100% up to date, and the storage requirements are low, since only a fraction of DBpedia needs to be stored locally (and only temporarily).
The figure below shows how DBpedia on Demand works. When a resource is requested (1), the corresponding Web page is retrieved from Wikipedia, as well as pages linking to the corresponding page (for extracting ingoing links) (2,3). The collected pages are passed to the DBpedia extraction framework (4) and an abstract extraction module (5) to compile the subset of DBpedia required.
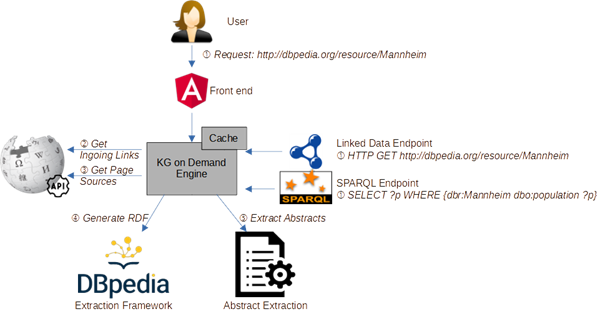
The extraction framework can be configured to extract the tailored subset of DBpedia required for the task at hand by including and excluding certain extractors (e.g., mapping-based properties, categories, GEO coordinates, etc.). Besides a graphical user interface, DBpedia on Demand has a Linked Data endpoint as well as a SPARQL interface capable of processing a limited set of SPARQL queries (particularly star-shaped queries).
Further links:
- Paper on arxiv: https://arxiv.org/abs/2107.00873
- Source code: https://github.com/mbrockmeier/KnowledgeGraphOnDemand
- Did you consider this information as helpful?
- Yep!Not quite ...